Trying Out LLaMA 3 (8B) on My Cheap VPS: A Fun Experiment with Ollama and OpenWebUI
I was curious about running a big language model like LLaMA 3 (8B) on a budget VPS, so I decided to give it a shot. It’s open-source, so why not? I used Ollama and OpenWebUI to set it up on my Contabo VPS. It wasn’t the most powerful server, but it was enough for a little experiment.
Setting It Up with Docker
To make things easier, I decided to use Docker to set everything up. Here’s how I did it:
- Installed Docker: First, I installed Docker on my hosting panel.
- Pulled the LLaMA 3 Model: Using Ollama within Docker, I downloaded the LLaMA 3 (8B) model.
- Configured OpenWebUI in Docker: I set up OpenWebUI using Docker as well.
- Launched the Model: After setting everything up in Docker, I started the model and connected it with OpenWebUI.
I followed this tutorial, but the difference is that I used my VPS, whereas in this YouTube video, he used his own local PC: https://www.youtube.com/watch?v=84vGNkW1A8s.
How My VPS Handled It
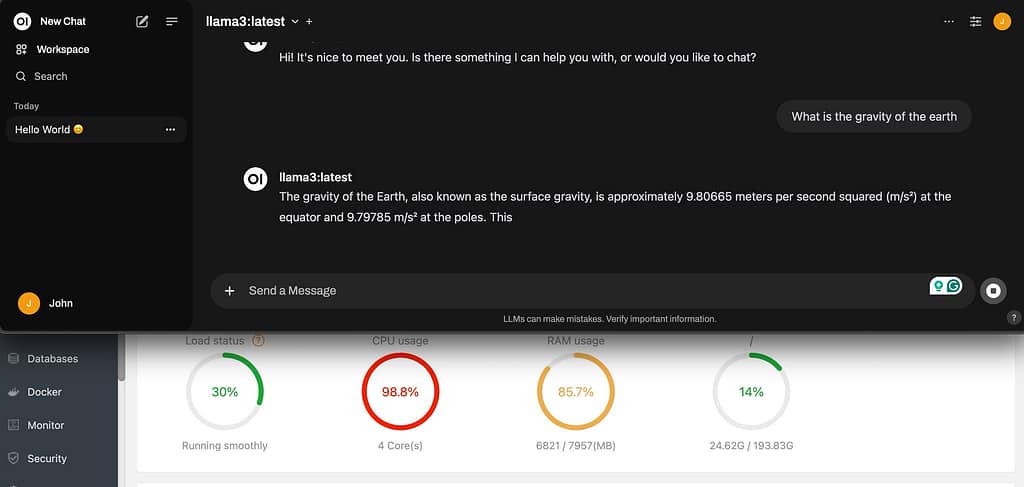
Once I had everything running, I tested the model by asking, “What is the gravity of the earth?” Here’s what happened with my VPS:
- CPU Usage: It spiked to 98.8% on all 4 cores. The model really made the CPU work hard.
- RAM Usage: It used up 6821 MB out of 7957 MB available. It was pushing the limits of my server’s memory.
This was a fun and educational experience. Running a model like LLaMA 3 on a budget VPS is doable, but it definitely uses a lot of resources. The CPU and RAM usage were high, even for a basic question. It showed me that while open-source models are accessible, they still need quite a bit of power to run well.
Overall, it was a cool experiment. If you’re into tech and have a cheap VPS lying around, give it a shot! Just be ready for some heavy CPU and RAM usage when you’re testing it out.